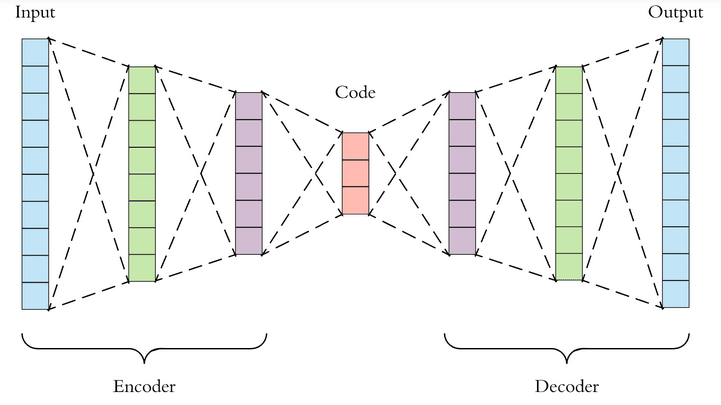
Fig -5 The general structure of an auto encoder
As you can see here we are taking the input with high features in the input layer, then we start compressing the dimension by reducing the neurons in the hidden layers and at the middle we get the encoded information. Now the same architecture is unrolled in the decoder side by increasing the number of neurons on subsequent hidden layers.
Anomalies are rare occurrences hence it is very difficult to obtain the data for training of models. Furthermore, anomalous behavior changes over time. Hence it becomes a necessity to classify the anomalous data at run time. Anomalies are rare occurrences hence it is very difficult to obtain the data for training of models. Furthermore, anomalous
behavior changes over time. Hence it becomes a necessity to classify the anomalous data at run time. Here our approach is to first train an auto encoder only on normal data. Then we will test the model on both normal and anomalous data. For the anomalous data, the Root Mean Square Error (RMSE) of the reconstructed data would be large.
Results and Discussion: ROC curves are a very useful tool for understanding the performance of classifiers. However, our case is a bit out of the ordinary. We have a very imbalanced dataset. Nonetheless, let’s have a look at our ROC curve:
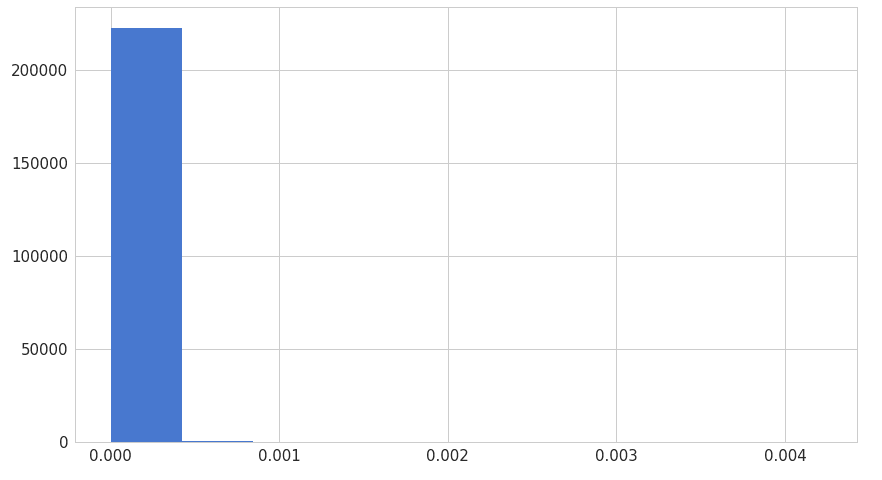
6(a). Error distribution of normal data
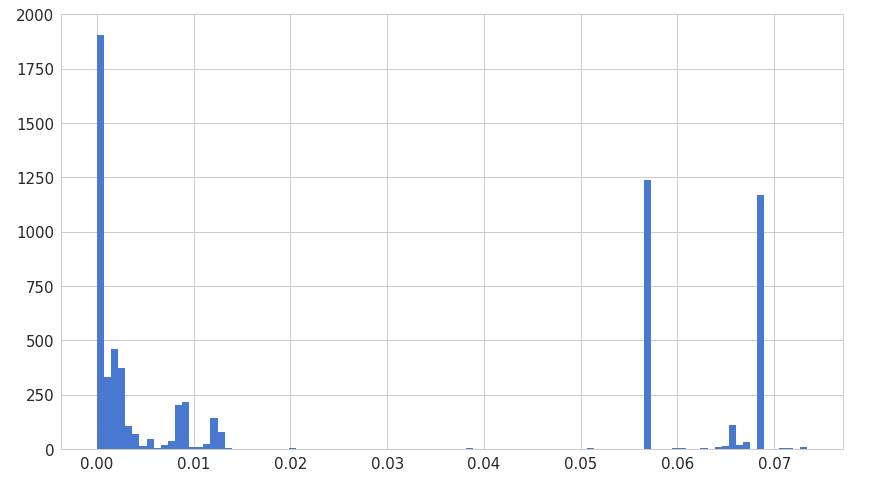
6(b). Error distribution of anomaly data
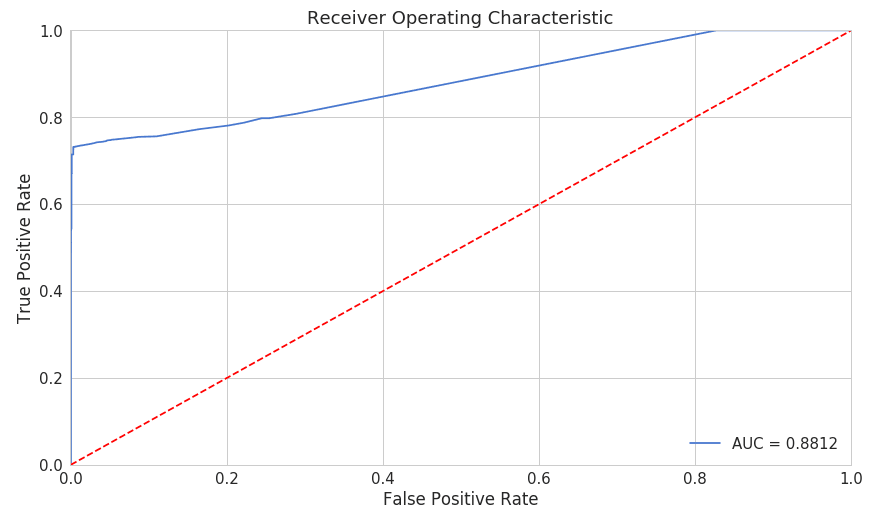
Fig -7: Evaluation of the model based on AUC
The ROC curve plot is the true positive rate versus the false positive rate, over different threshold values. Basically, in Fig-7, we want the blue line to be as close as possible to the upper left corner. While our results look quite good, also area under the curve (AUC) value is quite high (0.88).
For AUC, the higher the value the better the model is (So more it is closer to 1 better the model). Now since our Model is trained, we have to predict whether or not a new or unseen sequence of log messages in a different time intervals or different blocks are normal or anomaly.
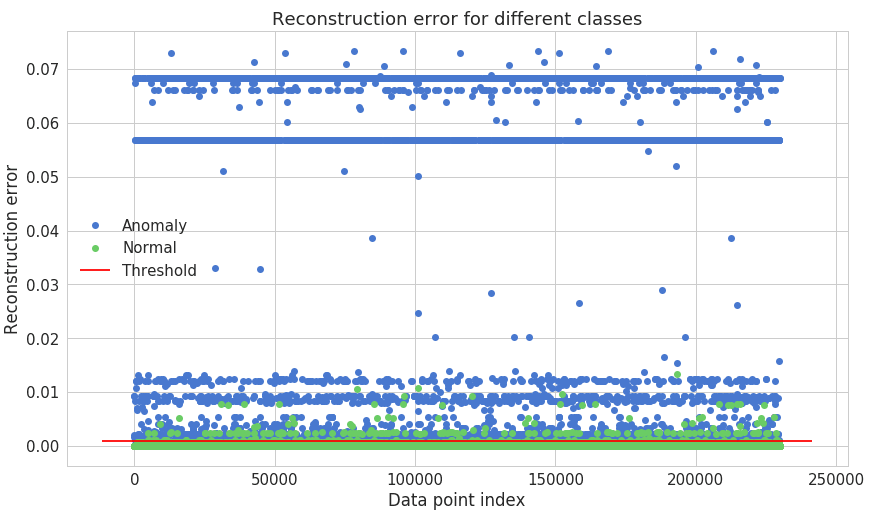
Fig – 8 Reconstruction error for the different classes
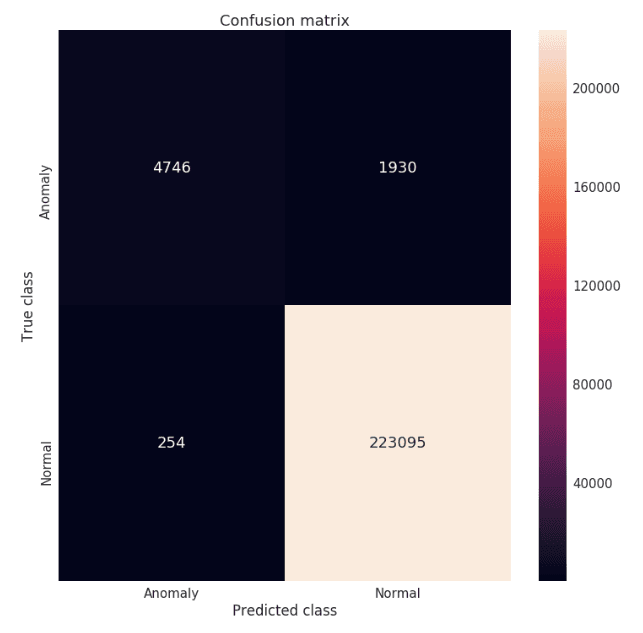
From confusion matrix in Fig-9, we have observed that our model seems to catch lot of anomalies. We have calculated precision, recall and F1 measure and the corresponding values are 0.94, 0.71, and 0.81. We can increase recall value by setting the threshold value lower than the previous one, which will decrease the fraction of anomalies misclassified as normal.