Data Set: Here we have considered HDFS (Hadoop Distributed File System) dataset, which has been obtained from a production Amazon EC2 system and is well suited for anomaly detection. Not only does it contain 11,175,629 log messages with 16,838 anomalies, the dataset is also pre-labeled by domain experts, which will be useful for identifying correctness of algorithms. A sample screen shot of the data is given below:
Methodology: We are following a three-step approach – log parsing, event matrix generation, and anomaly detection for finding the anomalies in a sequence of log messages. One thing to note here is that the sequence of log messages is generated by using either sliding window approach (i.e., slicing the data with three hours with one-hour stride) or detecting the identifier in the log message.
As observed in the sample data set, the raw log message contains two parts: constant part and variable part. The constant part constitutes the fixed plain text (wrote by the developer) and remains the same for every event occurrence, which can reveal the event type of the log message. The variable part carries the runtime information of interest (e.g., the IP address and port: 10.251.111.130:49851), which may vary among different event occurrences (variable part can be consider as a parameter). We will now see the three steps disused above more in details one by one:
b. Event Matrix Generation: Once we extract events from raw log messages then we form an event count matrix M, which will be fed into the anomaly detection model. This also helps to convert the textual log information to numeric representation which gets easier for the model for feed with this kind of data. In the event count matrix, each row represents a block or time window, while each column indicates one event type. The value in cell M_ij represents how many times event j occurs on block i or time stamp i. Instead of directly detecting anomaly on M, we have used term frequency and inverse document frequency (TFIDF) method, which assign lower weights to common event types, i.e. the events which are less likely to contribute to the anomaly detection process.
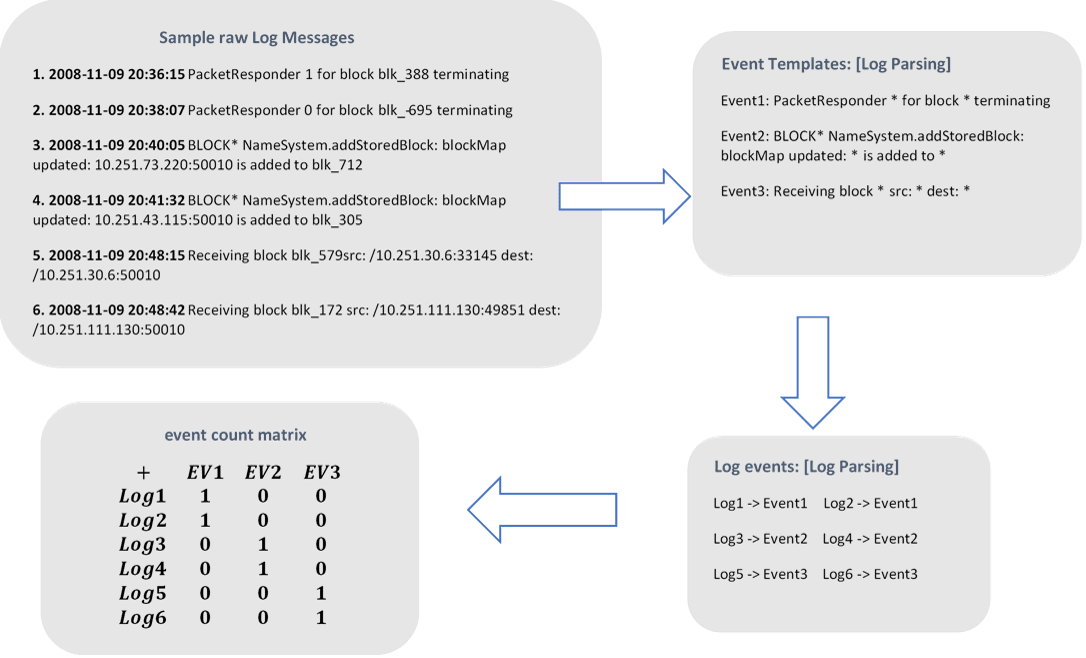
Fig -4 The Analysis Methodology

