There are multiple examples of system generated logs in use:
Traditionally, developers (or operators) often inspect the logs manually with keyword search and rule matching. The increasing scale and complexity of modern systems, however, has led to an exponential rise in the volume of logs, rendering manual inspection as a difficult and time-consuming effort.
To minimize this need for enhanced manual effort, many anomaly detection methods can be utilized. Before starting anomaly detection task, it is mandatory to do log parsing, i.e., converting the raw unstructured log data to a structure. Traditionally, log parsing relies heavily on regular expressions to extract the specific log event.
Since modern software systems are highly complex and they often produce huge amount of diverse log events, leveraging a trivial regular expression method for log parsing is not feasible for large data set. In our work, we have used various automated log parsing algorithms [1], [2], [3] and chose the best algorithm based on time and accuracy constraints.
Anomalies are patterns in a data that differs significantly with normal behavior of the data. There are different types of anomalies discussed by [4]:
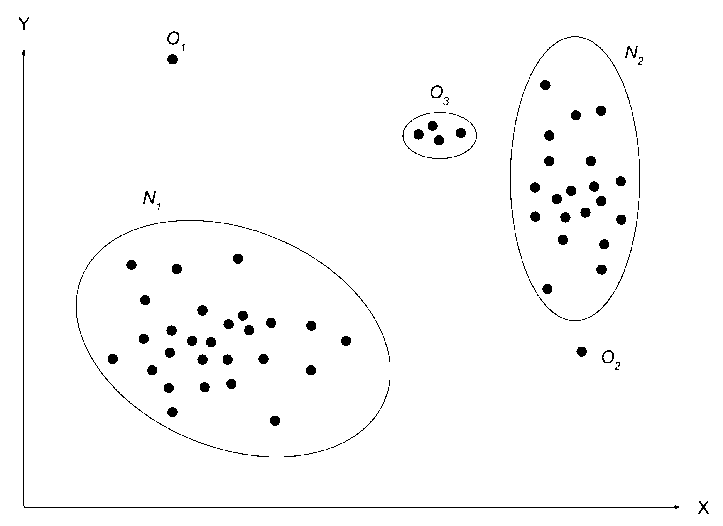
a. Point anomaly: A point anomaly is data which deviates significantly from the average or normal distribution of the rest of the data. A business use case could be Detecting Credit Card Fraud based on “Amount Spent”.
Fig -1 Example of point anomaly. O1 and O2 are point anomalies
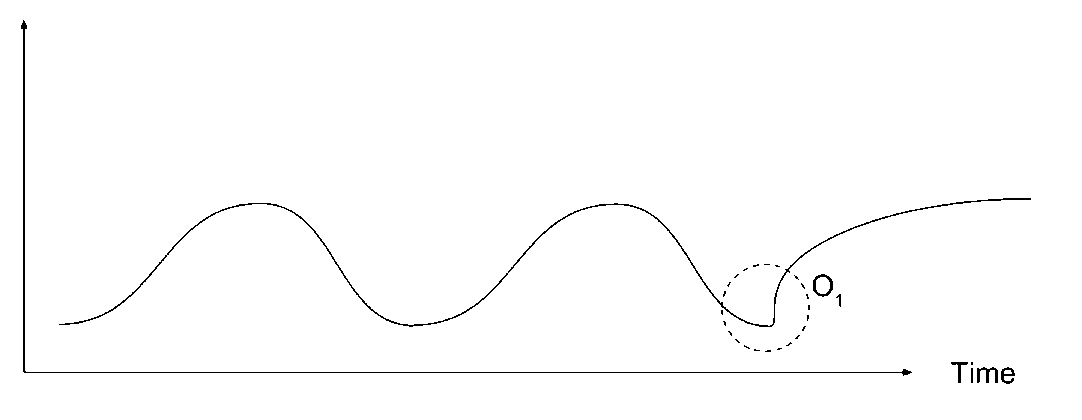
b. Contextual anomaly: A data instance that is anomalous in a specific context but not otherwise is termed as a contextual anomaly or conditional anomaly. This type of anomaly is most common in time series data. A business use case could be the instance where an increase in power consumption in residential area during summers is normal but may be anomalous for the rest of the year.
Fig -2 Example of Contextual Anomaly
Source: https://towardsdatascience.com/a-note-about-finding-anomalies-f9cedee38f0b
c. Collective anomaly: If a collection of related data instances is anomalous with respect to the entire data set, it is termed a collective anomaly. The individual data instances in a collective anomaly may not be anomalies by themselves, but their occurrence together as a collection is anomalous. A business use case could be a scenario where someone is trying to copy data form a remote machine to a local host without proper authorization – an anomaly that would be flagged as a potential cyberattack.
The point anomalies can occur in any data set, but collective anomalies occur in data sets where data instances are related. Occurrence of contextual anomalies depends on the availability of context attributes in the data. A point anomaly or a collective anomaly can also be a contextual anomaly if analyzed with respect to a context. Therefore, we can project any point anomaly detection problem or collective anomaly detection problem as contextual anomaly detection problem if the contexts are available in the data set.