
Figure 5: A Conventional CPU Architecture

Figure 6: Temporal Architecture
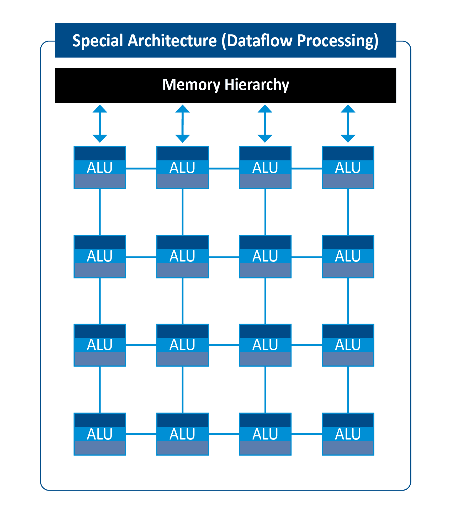
Figure 7: Spatial Architecture
Deep neural nets have computation overhead as they require a large amount of data for training. Apart from data forward step, needed for generation of new weights in training, error backward and gradient computation are two additional computation steps needed.
AI applications may require many servers during training. Such a setup is likely to increase with time for development and deployment-specific needs. An AI model development, for instance, may only need a few servers to train an initial model with real data and the subsequent training could require much larger servers as the data size increases (e.g., autonomous-driving models may require a large number of servers to reach desirable accuracy in detecting obstacles). As and when there is an increase in the size of training datasets and NNs, a single accelerator may no longer be capable of supporting the training. Since the training task involves input weights synchronization whenever model parameters change, programmable switches can route data in different directions to resynchronize input weights almost instantly and increase the training speed.
Remote Direct Memory Access (RDMA)
RDMA is a particularly useful feature for distributed computing and training complex models that involves directly accessing memory from another computer without using either of the computer’s operating systems. A prominent example of RDMA is the Intel-acquired, Israel-based startups, Habana’s Goya and Gaudi accelerators, which support such a mechanism.
AI models are compute-intensive and need the right AI hardware architecture and cores to perform thousands of mathematical processes called matrix multiplication. The multiply-and-accumulate (MAC) operations, which are a fundamental component of both the convolution and fully connected layers, can easily be parallelized using parallel computing paradigms. Due to the inherent limitations of general-purpose processing chips, as discussed in the previous section, for AI workloads, it is often necessary to design specialized chips with which novel architectures can witness improved performance. A few key aspects of compute include:
AI applications have high memory-bandwidth requirements, as computing layers within deep neural networks are very demanding. This is because of the need to pass data between cores as quickly as possible. Therefore, these transactions can consume up to 95% of the energy needed to do machine learning and AI. Memory is required to store input data and weight and perform various other functions during both AI training and inferencing. Each MAC requires multiple memory reads (for filter weight, FMAP activation, and partial sums) and at-least one memory write. Therefore, every time a piece of data is moved from an expensive energy level to a lower-cost level, it must be reused as much as possible to minimize subsequent accesses to the expensive levels.
On-Chip Memory
Data access outside of chip memory takes more time than memory on the same chip. Hence, on-chip memory applications are seen as viable alternatives. There are a few prominent use cases of this technology in the market already: Bristol-based Graphcore’s Intelligence Processing Unit (IPU) architecture can hold an entire ML model inside the processor, while researchers at Stanford University have designed a DNN inference system, termed Illusion, that consists of eight networked computing chips, each of which contains a certain minimal amount of local on-chip memory and mechanisms for quick wakeup and shutdown. The system tricks the hybrids into thinking they are one chip and hence referred to as Illusion System.


