The team used NVIDIA GeForce RTX 2080 (8 GPUs) for training models. It took an inhouse curated dataset comprising of 2,70,000 chest x-ray images and passed them through the CheXpert labeler to generate the ground truth labels. It was found that the ~1,90,000, images correspond to normal chest X-Ray and the rest ~80,000 contain one or more abnormality.

Table 1. Report Labeler result of Top 5 classes
As evident from the table, Mi model performs the best for Ci class but not for Cj class. This is because each class corresponds to different pathology which can correspond to different regions in the image (Cardiomegaly in the heart region, Pleural Effusion in the bottom) or can be diffused radiological finding (Edema) meaning that it covers the entire lung region (image) and can’t be localized to a given region.
Table 2 shows the comparison of the performance of our model with the other existing models for the different chest X-ray datasets.
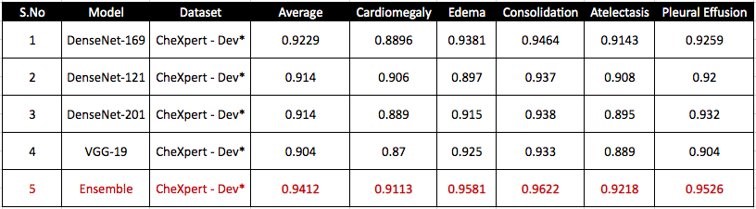
Table 2. Multilabel classification on CheXpert datasets
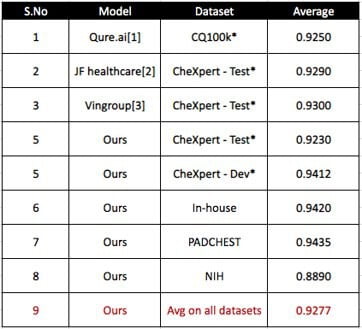
Table 3. Multilabel classification comparison with SOTA
3.3 Report Generation
The team initially considered training the proposed decoder model using the Indiana University Dataset as it is a publicly available free dataset. However, it was observed that for each category we got less than 7470 images (Consolidation had a maximum of 496 images). The team conducted a small experiment and observed that the model was clearly underfitting (Max BLEU score obtained was Consolidation for 0.2196). Because of this reason, we decided to go for the in-house dataset which had many more images per label.
The team took the best performing classification model for each class as the encoder. ¡Write the parameters used for Attention base LSTM. While training the decoder, it froze the weights of the encoder, to ensure that there is no drop in the classification accuracy. While training the decoder, it only used the sentence corresponding to the label and not the entire impression.
This was deemed correct because the encoded features only contain the information about the given label and not the other labels present in the image. Other models that correspond to the different labels will generate the corresponding sentence for those labels. The final impression will be the concatenation of all such sentences.
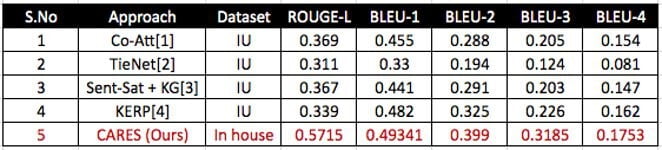
Table 4 Report Generation Model Comparison with SOTA
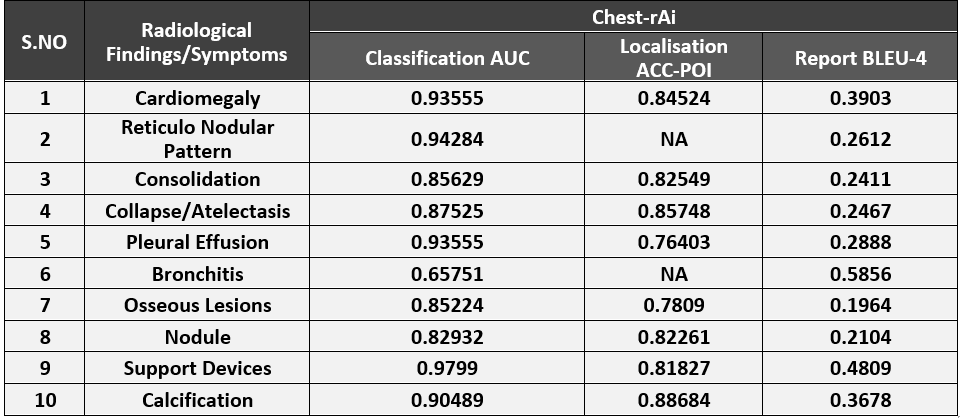
Table 5 Model Evaluation on inhouse dataset for classification, localisation and report generation.

Table 6 Report Generation Model using RFQI

Figure 4. RFQI: Novel Scoring Mechanism
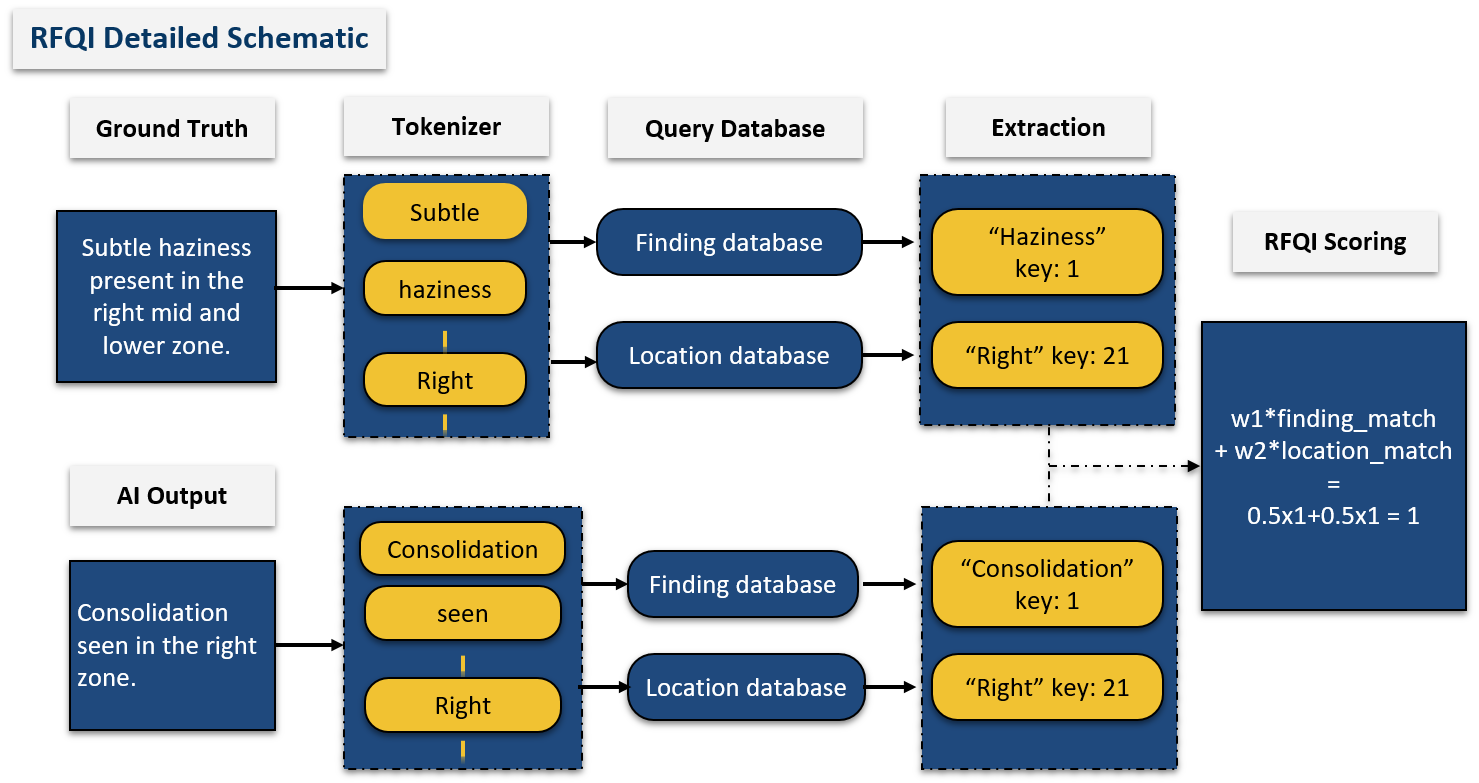
Figure 5. RFQI Detailed Schematic